16-824 Visual Learning and Recognition: Homework 3 · Spring 2023 · GITHUB
About The Project
Implemented and trained different components of a Transformer decoder for image captioning using a subset of the COCO dataset. Additionally, a Vision Transformer (ViT) was implemented for classification on CIFAR10.
Built With
- Python
- NumPy
- Pytorch
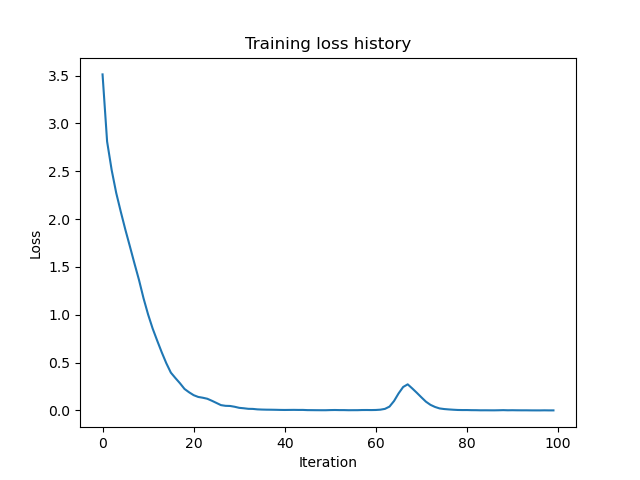
Results
For the entire report, please refer to the Documentation